解析技术基础准备
HTML结构认知
HTML文档就像网页的骨架,由各种标签构成层级结构。例如:
<!DOCTYPE html>
<html>
<head>
<title>示例页面</title>
</head>
<body>
<div class="content">
<h1 id="main-title">欢迎学习Python解析</h1>
<ul class="list">
<li>第一项</li>
<li>第二项</li>
</ul>
</div>
</body>
</html>开发者工具实战
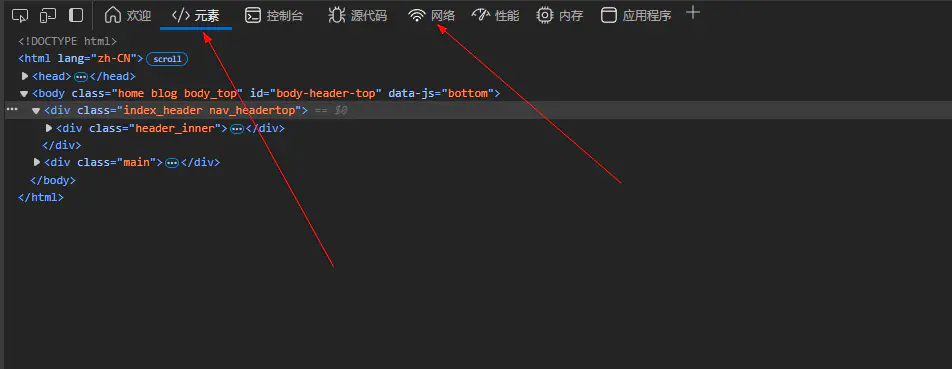
在浏览器中按F12打开开发者工具:
- Elements:查看网页DOM结构
- Network:监控网络请求(重要!)
- 使用技巧:右键元素 -> 检查,快速定位代码位置
BeautifulSoup解析实战
环境安装
pip install beautifulsoup4基础解析方法
from bs4 import BeautifulSoup
import requests
html = """
<html>
<body>
<div class="product">
<h2>Python编程书</h2>
<p class="price">¥59.00</p>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
# 获取标题文本
title = soup.find('h2').text
print(f"书名:{title}")
# 获取价格
price = soup.find('p', class_='price').text
print(f"价格:{price}")结果输出为:
书名:Python编程书
价格:¥59.00CSS选择器进阶
# 选择所有<li>标签
items = soup.select('li')
# 选择class为product的div
products = soup.select('div.product')
# 层级选择器
price = soup.select('div.product > p.price')[0].text美图实战案例-beatifulsoup
我们在某浏览器找到一个小姐姐的美图网站,为什么是小姐姐网站,因为sese是前进的动力,嘿哈…
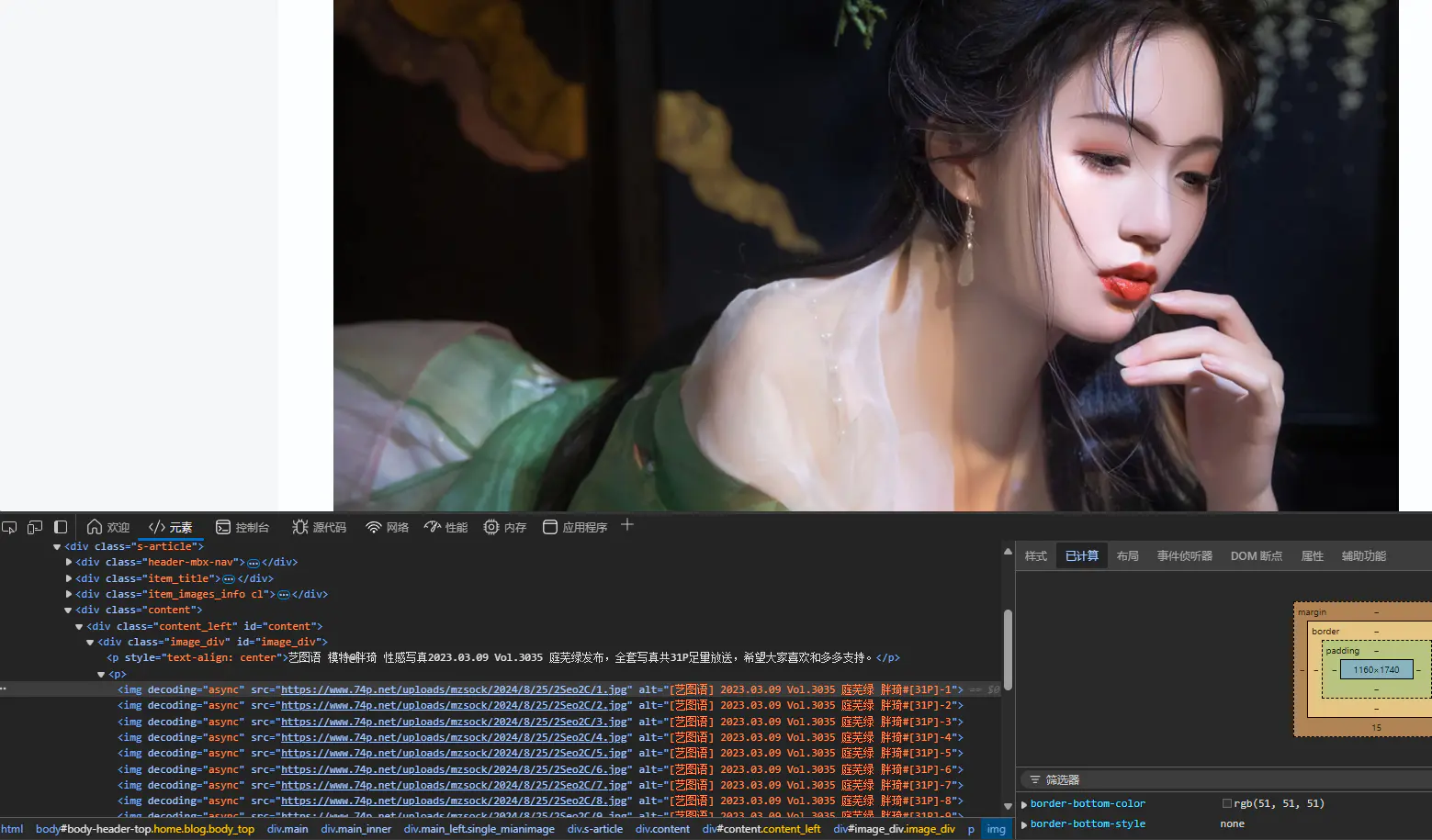
可以看见该网站的结构还是挺简单的,图片主要放在一个div的p标签的img标签中,由此,我们根据BeautifulSoup写出图片的提取规则:
# 方式一:通过父容器精准定位
image_div = soup.find('div', id='image_div')
img_tags = image_div.find_all('img')
image_links = [img['src'] for img in img_tags]
# 方式二:直接查找所有图片(通用方法)
# img_tags = soup.find_all('img', {'decoding': 'async'})
# image_links = [img['src'] for img in img_tags]
接下来是标题,先看其网页结构:
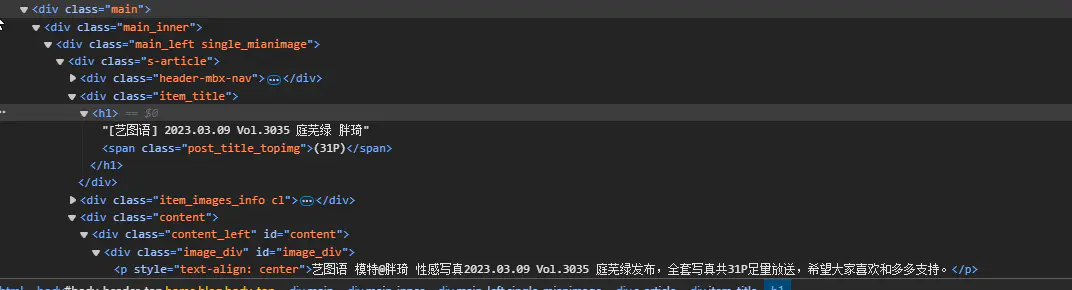
很明显,标题在h1标签中,以此我们构建标题的规则为:
title_div = soup.find(‘div’, class_=’item_title’)
# 方法一:精准定位并移除span标签
h1_tag = title_div.find('h1')
# 移除不需要的span内容
if h1_tag.span:
h1_tag.span.decompose()
title = h1_tag.get_text(strip=True)
print("方法一提取结果:", title) # 输出:[艺图语] 2023.03.09 Vol.3035 庭芜绿 胖琦
# 方法二:直接提取并分割字符串(更简洁)
full_text = title_div.h1.get_text(strip=True)
clean_title = full_text.split('(')[0].strip()
print("方法二提取结果:", clean_title) # 输出同上再用我们所设计好的下载函数,将图片下载到标题相应的文件夹中即可。以下是下载该页图片的完整代码,使用beatifulsoup。
from bs4 import BeautifulSoup
import functions.func_main as fun
url='https://www.74p.net/meitu/12079'
resp=fun.get_request_text(url)
soup = BeautifulSoup(resp, 'html.parser')
# 获取标题文本
title_div = soup.find('div', class_='item_title')
full_text = title_div.h1.get_text(strip=True)
clean_title = full_text.split('(')[0].strip()
print("标题:", clean_title) # 输出同上
#获取图片链接列表
img_tags = soup.find_all('img', {'decoding': 'async'})
print(img_tags,f'共找到图片{len(img_tags)}张图片!')
# 提取 src 属性
image_links = [img['src'] for img in img_tags]
#下载图片列表
fun.download_images(image_links, f'I:\\{clean_title}')XPath与lxml高效解析
另一种常用解析方法是使用lxml库中的xpath法则,首先我们要了解xpath法则的一些基础含义:
| 表达式 | 说明 |
|---|---|
| / | 从根节点选取 |
| // | 匹配任意层级 |
| @ | 选取属性,如img标签里的src |
| * | 匹配任意元素 |
| [n] | 第n个元素 |
以上表达式可以自行组合使用,如采用//*代表从根节点开始匹配任意元素。
同样是上面的代码,我们使用xpath解析图集标题和图片链接,首先是图片标题:
title=tree.xpath('//*[@class="item_title"]/h1/text()')[0]其次是图片链接:
srcs=tree.xpath('//*[@class="image_div"]/p/img/@src')可见lxml使用xpath提取元素会更简洁,以下是完整代码:
from lxml import etree
import functions.func_main as fun
url='https://www.74p.net/meitu/12079'
resp=fun.get_request_text(url)
#解析为可以被xpath提取的对象
tree=etree.HTML(resp)
#提取标题
title=tree.xpath('//*[@class="item_title"]/h1/text()')[0]
print(title)
#提取图片
srcs=tree.xpath('//*[@class="image_div"]/p/img/@src')
print(srcs,len(srcs))
fun.download_images(srcs, f'I://{title}')最后可以略微查看我们的下载成果,满足sese的初始目的,嘿嘿…