你还不知道怎么使用deepseek,这篇文章可以给你一些初步的解答。
DeepSeek注册与API获取全攻略
官网直连
普通用户使用deepseek很简单,直接进入官网:DeepSeek – 探索未至之境,登录即可使用,不过因为种种原因,deepseek的官方服务器响应力不足,所以大家也可以使用一些deepseek平替,以下是我为大家整理的几个deepseek平替平台:
- 腾讯元宝:https://yuanbao.tencent.com/
- 超算互联网:https://www.scnet.cn/ui/chatbot/#/home
- 浙江大学大先生:https://chat.zju.edu.cn/
- 跃问:https://yuewen.cn/chats/new
- 天工AI:https://www.tiangong.cn/
- 华为小艺:https://xiaoyi.huawei.com/chat/
注册登录这里以官网举例,进入官网注册登录界面:DeepSeek – 探索未至之境
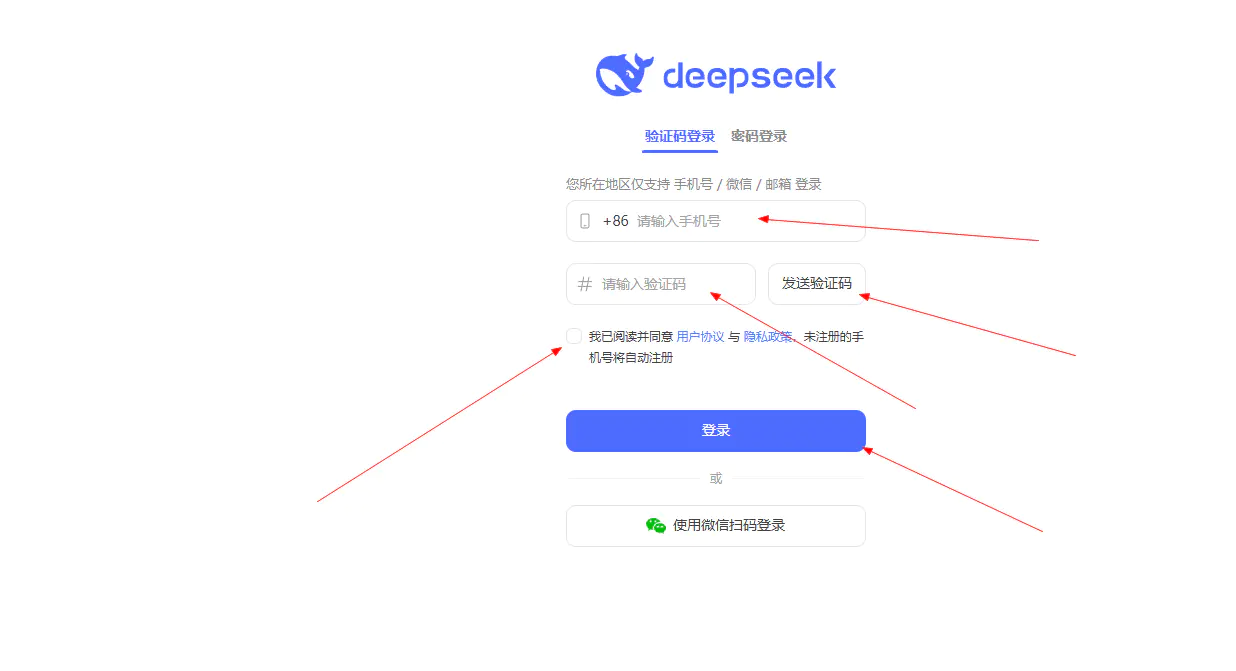
填写手机号后,点击发送验证码,将接收到的验证码填入验证码框,然后选择同意协议,最后点击登录即可。
有开发能力的用户,可以登录后进入开发者中心。

根据需求选择模型(如 R1 或 V3),生成 API 密钥即可。

deepseek的优势很大,在文本处理长度上,支持长文本,V3 模型支持 32k 上下文窗口,适合处理长篇文档。在价格上,R1 模型调用成本为 16 元/百万 Token,官网提供实时用量统计,且不同时段还有优惠。
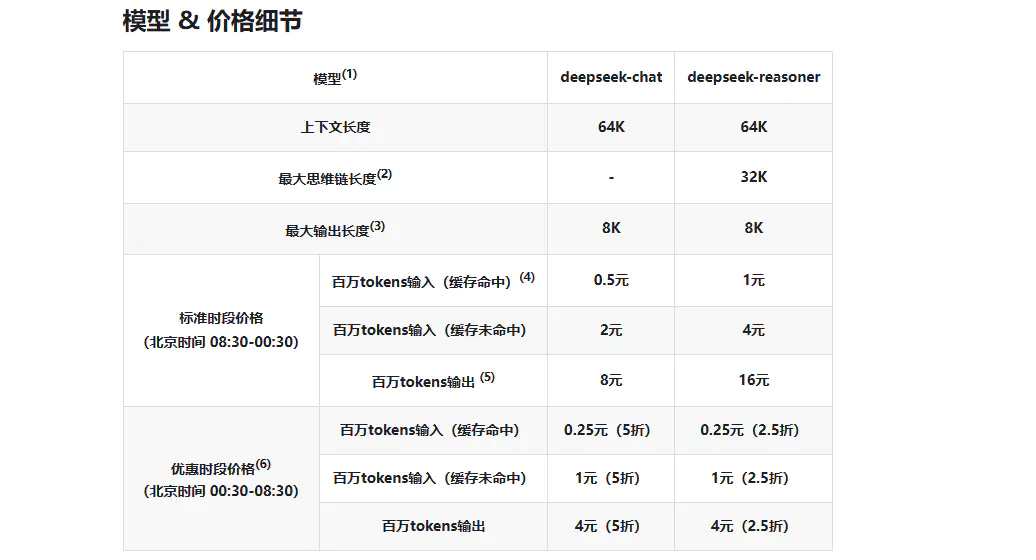
另外,用户需完成实名认证,新用户首月赠送 50 万 Token,建议赠送的Token优先用于测试。
第三方平台推荐
- 硅基流动(SiliconFlow):学生用户凭 .edu 邮箱可领取 15 万免费 Token,适合学术研究。
- 火山引擎(火山方舟):推理速度达 68 Token/s,每日提供 500 次免费商用调用,适合企业高频需求。
- GitHub Models:通过 GitHub Token 授权可免费调用 DeepSeek-R1,开发者社区首选。
网页端与 APP 端操作对比
界面与操作差异
| 维度 | 网页端 | APP 端 |
|---|---|---|
| 访问方式 | 浏览器直接输入网址(无需安装) | 需下载安装(iOS/Android) |
| 核心功能 | 支持多标签页操作,适合多任务处理 | 内置文件管理器,支持本地文档上传与离线缓存 |
| 交互体验 | 适配 PC/平板分辨率,快捷键操作流畅 | 手势交互优化(如滑动返回),支持语音输入 |
功能侧重点分析
在数据处理方面,网页端支持Excel/CSV 文件批量导入,自动清洗异常值;在隐私保护方面,APP端采用硬件级加密技术,生物识别(指纹/面部)解锁敏感操作。根据这种功能的不同侧重点,如果是临时需求,推荐使用网页端,即开即用,响应速度更快;如果是长期使用,如项目管理,APP端也支持数据云端同步,可以多设备无缝衔接使用。
三大核心功能简单演示
文本生成(周报/邮件/报告)
为了提高生成的准确率,我们可以采用指定风格关键词(如“商务/技术/创意”)的方式来进行提示词输入,如:
生成一份技术向的季度报告,需包含代码性能优化方案,用 Markdown 分点呈现[9](@ref)。这就是所谓的结构化模版,该模版为:背景 + 需求 + 格式要求
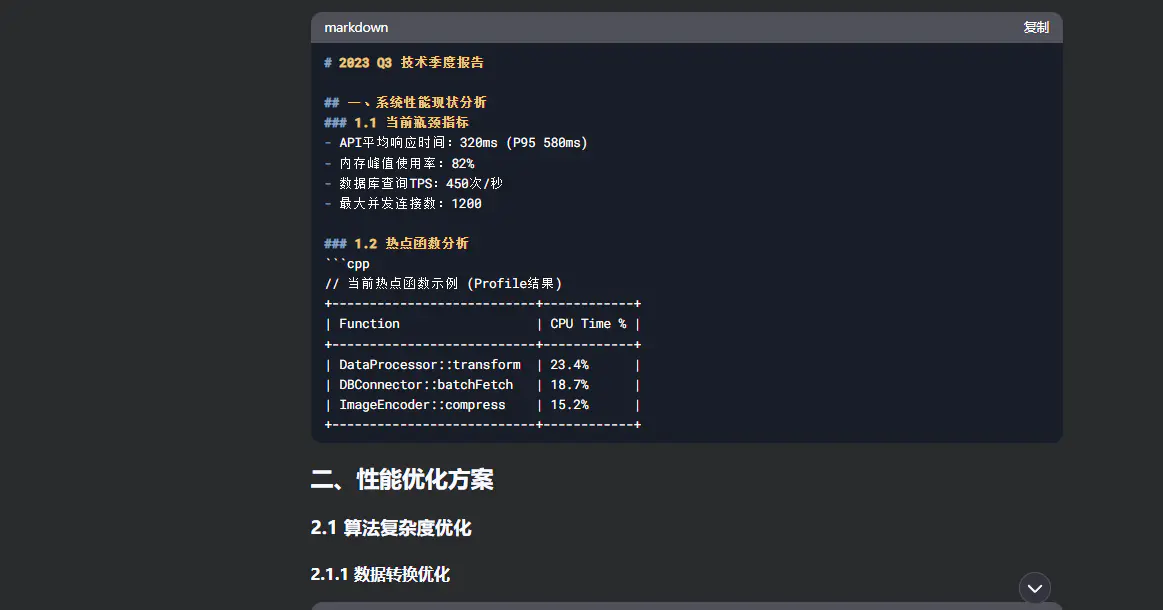
数据分析与可视化
上传 Excel 文件,输入指令(如“分析销售数据”),我们这里以一份网上寻找的销售文档作为测试。

如果需要数据可视化,则需要一定的编程基础,将它和python结合起来,接下来我们就尝试使用以上表格,让它给我们一个python可视化代码,然后我们运行出一个可视化柱状图来。
代码调试与优化
打开一个deepseek,传入xlsx文件,然后输入指令:
请为我分析该图表中的销售数据,并使用python代码为生成该销售数据的柱状图,注意数据的一致性和正确性,防止python代码运行出错第一次deepseek给出的代码,当我们使用python运行时,发现其汉字无法正常显示。
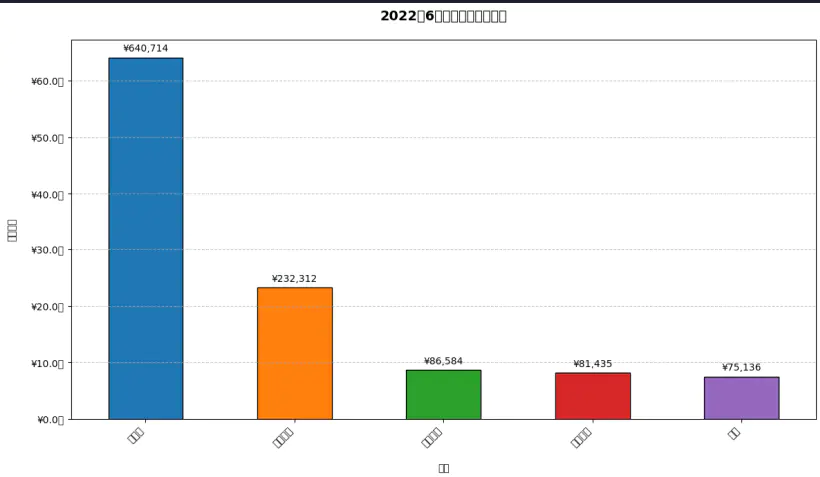
所以我们接着要求他解决这个问题:
运行你给出的代码,其中的汉字无法在图表中显示,请为我修改代码,让汉字可以正常显示然后它给出新的代码,新增了字体配置,我们的图表就正常了:
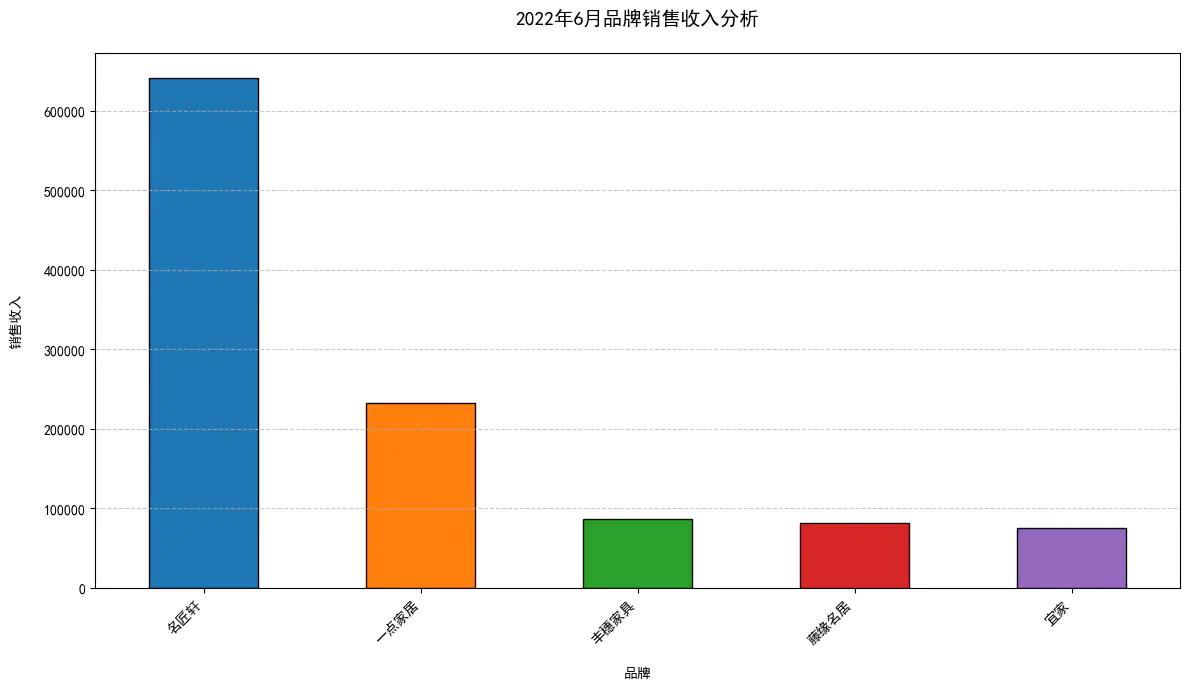
以下是完整代码,当然,需要一定的python基础:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
# ======================
# 数据准备与校验模块
# ======================
def validate_data(df):
"""执行数据质量检查"""
# 检查必需字段是否存在
required_cols = ['品牌', '销售单价', '销售数量']
missing_cols = [col for col in required_cols if col not in df.columns]
if missing_cols:
raise ValueError(f"缺失关键字段: {missing_cols}")
# 检查数值型字段有效性
numeric_cols = ['销售单价', '销售数量']
for col in numeric_cols:
if not pd.api.types.is_numeric_dtype(df[col]):
invalid_values = df[~df[col].apply(lambda x: str(x).replace('.','',1).isdigit())][col].unique()
raise ValueError(f"无效数值字段 {col}:发现非数字值 {invalid_values}")
# 检查品牌名称一致性
valid_brands = ['藤缘名居', '一点家居', '丰穗家具', '名匠轩', '宜家']
invalid_brands = df[~df['品牌'].isin(valid_brands)]['品牌'].unique()
if len(invalid_brands) > 0:
raise ValueError(f"无效品牌名称: {invalid_brands}")
# ======================
# 数据加载(模拟真实Excel结构)
# ======================
# 根据用户提供的Excel结构构建DataFrame
raw_data = [
# 藤缘名居 7条记录
{'品牌':'藤缘名居', '销售单价':159, '销售数量':50},
{'品牌':'藤缘名居', '销售单价':299, '销售数量':25},
{'品牌':'藤缘名居', '销售单价':530, '销售数量':35},
{'品牌':'藤缘名居', '销售单价':288, '销售数量':10},
{'品牌':'藤缘名居', '销售单价':540, '销售数量':14},
{'品牌':'藤缘名居', '销售单价':159, '销售数量':120},
{'品牌':'藤缘名居', '销售单价':299, '销售数量':60},
# 一点家居 13条记录
{'品牌':'一点家居', '销售单价':1758, '销售数量':30},
{'品牌':'一点家居', '销售单价':690, '销售数量':16},
{'品牌':'一点家居', '销售单价':570, '销售数量':36},
{'品牌':'一点家居', '销售单价':1088, '销售数量':15},
{'品牌':'一点家居', '销售单价':528, '销售数量':20},
{'品牌':'一点家居', '销售单价':1638, '销售数量':19},
{'品牌':'一点家居', '销售单价':1758, '销售数量':5},
{'品牌':'一点家居', '销售单价':690, '销售数量':15},
{'品牌':'一点家居', '销售单价':570, '销售数量':15},
{'品牌':'一点家居', '销售单价':1088, '销售数量':50},
{'品牌':'一点家居', '销售单价':528, '销售数量':15},
# 丰穗家具 10条记录
{'品牌':'丰穗家具', '销售单价':400, '销售数量':10},
{'品牌':'丰穗家具', '销售单价':348, '销售数量':8},
{'品牌':'丰穗家具', '销售单价':650, '销售数量':20},
{'品牌':'丰穗家具', '销售单价':970, '销售数量':18},
{'品牌':'丰穗家具', '销售单价':960, '销售数量':5},
{'品牌':'丰穗家具', '销售单价':400, '销售数量':8},
{'品牌':'丰穗家具', '销售单价':348, '销售数量':20},
{'品牌':'丰穗家具', '销售单价':650, '销售数量':16},
{'品牌':'丰穗家具', '销售单价':970, '销售数量':14},
{'品牌':'丰穗家具', '销售单价':650, '销售数量':16},
# 名匠轩 18条记录
{'品牌':'名匠轩', '销售单价':996, '销售数量':35},
{'品牌':'名匠轩', '销售单价':3698, '销售数量':25},
{'品牌':'名匠轩', '销售单价':695, '销售数量':30},
{'品牌':'名匠轩', '销售单价':480, '销售数量':42},
{'品牌':'名匠轩', '销售单价':690, '销售数量':32},
{'品牌':'名匠轩', '销售单价':2498, '销售数量':27},
{'品牌':'名匠轩', '销售单价':1098, '销售数量':10},
{'品牌':'名匠轩', '销售单价':818, '销售数量':8},
{'品牌':'名匠轩', '销售单价':996, '销售数量':8},
{'品牌':'名匠轩', '销售单价':3698, '销售数量':7},
{'品牌':'名匠轩', '销售单价':695, '销售数量':10},
{'品牌':'名匠轩', '销售单价':480, '销售数量':24},
{'品牌':'名匠轩', '销售单价':690, '销售数量':50},
{'品牌':'名匠轩', '销售单价':2498, '销售数量':28},
{'品牌':'名匠轩', '销售单价':1098, '销售数量':80},
{'品牌':'名匠轩', '销售单价':818, '销售数量':28},
{'品牌':'名匠轩', '销售单价':996, '销售数量':28},
{'品牌':'名匠轩', '销售单价':2498, '销售数量':28},
# 宜家 8条记录
{'品牌':'宜家', '销售单价':100, '销售数量':28},
{'品牌':'宜家', '销售单价':180, '销售数量':50},
{'品牌':'宜家', '销售单价':688, '销售数量':35},
{'品牌':'宜家', '销售单价':480, '销售数量':28},
{'品牌':'宜家', '销售单价':100, '销售数量':28},
{'品牌':'宜家', '销售单价':180, '销售数量':50},
{'品牌':'宜家', '销售单价':688, '销售数量':12},
{'品牌':'宜家', '销售单价':480, '销售数量':12},
]
df = pd.DataFrame(raw_data)
# 执行数据校验
try:
validate_data(df)
print("数据校验通过")
except ValueError as e:
print(f"数据校验失败: {str(e)}")
exit()
# ======================
# 数据计算模块
# ======================
# 计算销售金额
df['销售金额'] = df['销售单价'] * df['销售数量']
# 按品牌汇总(保留原始精度)
brand_sales = df.groupby('品牌', observed=True)['销售金额'].sum().sort_values(ascending=False)
# ======================
# 可视化模块
# ======================
plt.figure(figsize=(12, 7))
ax = brand_sales.plot(kind='bar',
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728', '#9467bd'],
edgecolor='black')
# 设置科学计数法格式
ax.yaxis.set_major_formatter(
ticker.FuncFormatter(lambda x, pos: f'¥{x/10000:.1f}万')
)
# 添加数据标签
for p in ax.patches:
ax.annotate(f'¥{p.get_height():,.0f}',
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center',
xytext=(0, 9),
textcoords='offset points')
# 新增字体配置
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用字体
# plt.rcParams['font.sans-serif'] = ['Hiragino Sans GB'] # Mac系统常用字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# ======================
# 可视化模块
# ======================
plt.figure(figsize=(12, 7))
ax = brand_sales.plot(kind='bar',
color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728', '#9467bd'],
edgecolor='black')
# 图表样式设置
plt.title('2022年6月品牌销售收入分析', pad=20, fontsize=14, fontweight='bold')
plt.xlabel('品牌', labelpad=15)
plt.ylabel('销售收入', labelpad=15)
plt.xticks(rotation=45, ha='right')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
# 显示图表
plt.show()
# ======================
# 数据验证输出
# ======================
print("\n品牌销售数据验证:")
print(brand_sales.apply(lambda x: f"¥{x:,.2f}").to_string())安全与合规指南
- 频率限制:免费版 API 调用上限为 5 次/秒,超频将触发熔断机制。
- 商业认证:企业用户需提交营业执照和用途说明,审核通过后方可商用。
- 数据合规:欧盟用户需启用 GDPR 兼容模式(设置 → 隐私选项)
至于通过调用deepseek的api接口,然后配置自己的专属程序用来做各种工作,我之前尝试过调用deepseek的示例接口,结果没法接通,还是官网算力太紧凑或者之前被攻击的缘故吧。
APIStatusError: Error code: 402 - {'error': {'message': 'Insufficient Balance', 'type': 'unknown_error', 'param': None, 'code': 'invalid_request_error'}}如果你有兴趣,可以访问其api文档进行部署:首次调用 API | DeepSeek API Docs