一、前言
Flux Lora 模型在 AI 绘画、图像生成等领域展现出强大潜力,其高效生成高质量图像的能力,正被广泛应用于个性化创作、虚拟场景构建等场景。但稳定的部署环境是模型训练与推理的基础,无论你是初次接触 AI 模型的爱好者,还是希望拓展技能的开发者,本文都将以 Windows 系统为例,提供从入门到实战的全流程指南。其他系统用户可参考关键逻辑调整命令,轻松完成部署。
二、部署前的准备工作
在开始部署前,需确认硬件与软件基础条件。硬件方面,建议配备支持 CUDA 的 Nvidia 显卡(如 RTX 3060 及以上)以保障训练效率,同时确保系统拥有至少 12GB 内存和 20GB 以上硬盘空间(含模型存储)。软件层面,需提前安装 Git(用于代码克隆,下载地址:https://git-scm.com/)和 Python 3.10+(需添加到环境变量,下载地址:https://www.python.org/),为后续操作奠定基础。
强烈推荐python 3.10版本,比较稳定不容易出问题。
三、部署
首先打开命令行工具,在指定路径创建项目文件夹并进入,通过以下命令克隆 Fluxgym 主项目。
git clone https://github.com/cocktailpeanut/fluxgym完成后需继续克隆 sd-scripts 工具库,切换到 fluxgym 目录后执行:
git clone -b sd3 https://github.com/kohya-ss/sd-scripts注意指定sd3分支以确保兼容性,后续若版本更新需留意分支变化。

接下来创建并激活虚拟环境以避免依赖冲突。
Windows 用户创建环境:
python -m venv env激活环境(激活后命令行前缀显示 “env”):
env\Scripts\activateLinux/macOS 用户创建环境:
python3 -m venv envLinux/macOS 用户激活环境:
source env/bin/activate。激活环境后进入 sd-scripts 目录,使用pip install -r requirements.txt安装sd-scripts的依赖。国内用户可添加清华源加速(-i https://pypi.tuna.tsinghua.edu.cn/simple),若遇版本问题可通过pip install –upgrade pip升级 pip。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple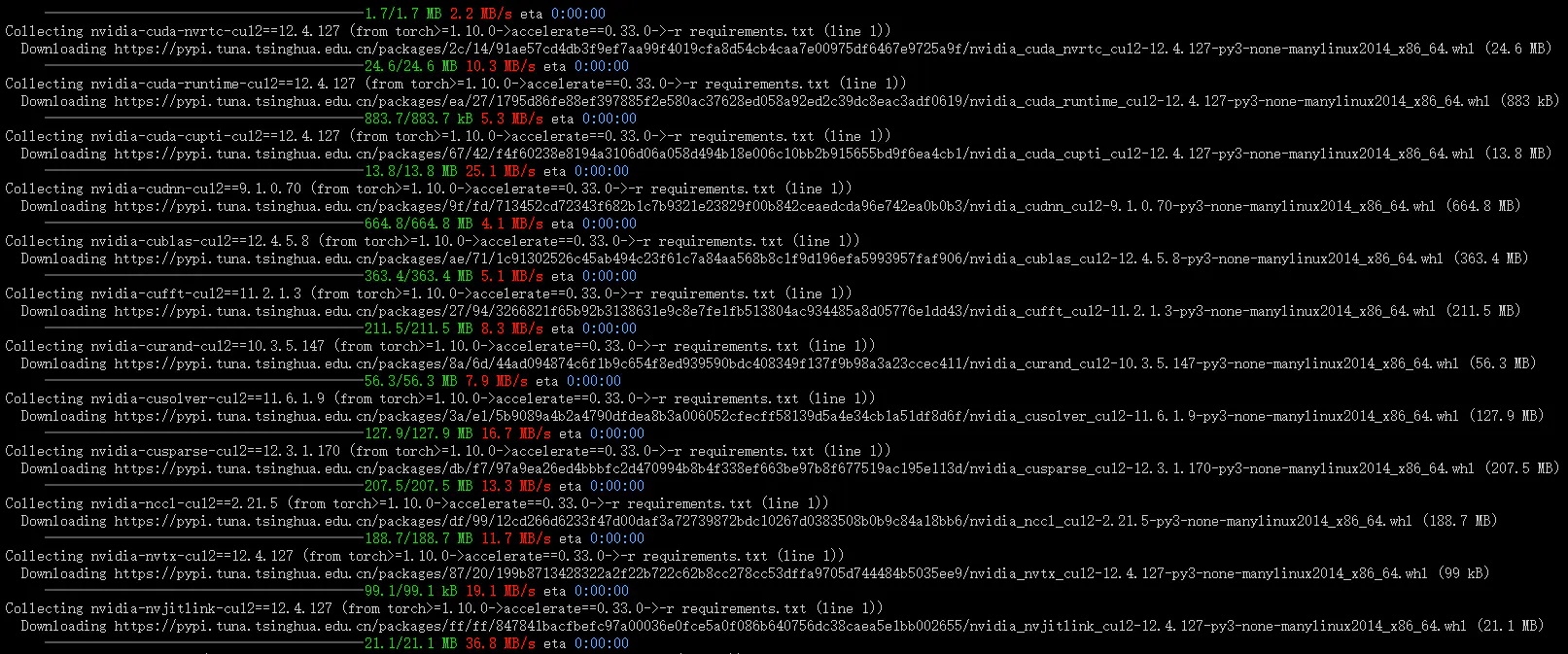
回到fluxgym文件夹,安装fluxygm的依赖,由于国内访问 Hugging Face 源速度较慢,需修改依赖文件。
用文本编辑器打开 fluxgym 目录下的 requirements.txt,将gradio_logsview@https://huggingface.co替换为gradio_logsview@https://hf-mirror.com,保存后执行命令安装依赖:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple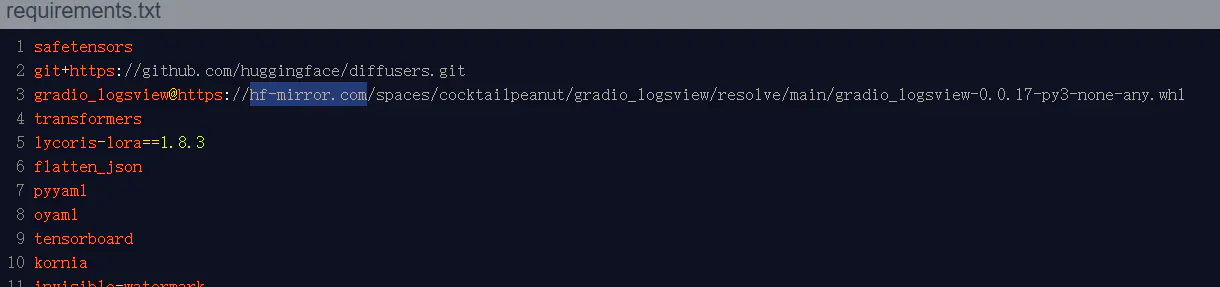
最后安装 PyTorch CUDA 版本,执行注意通过nvidia-smi命令查看显卡支持的 CUDA 版本,确保与cu121匹配。
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu121,完成依赖安装后,返回 fluxgym 主目录启动服务。
Windows 用户可以自己指定端口:
set GRADIO_SERVER_NAME=0.0.0.0
set GRADIO_SERVER_PORT=8080Linux/macOS 用户指定端口,用export替代set即可。
最后执行命令启动 Web 服务:
python app.py
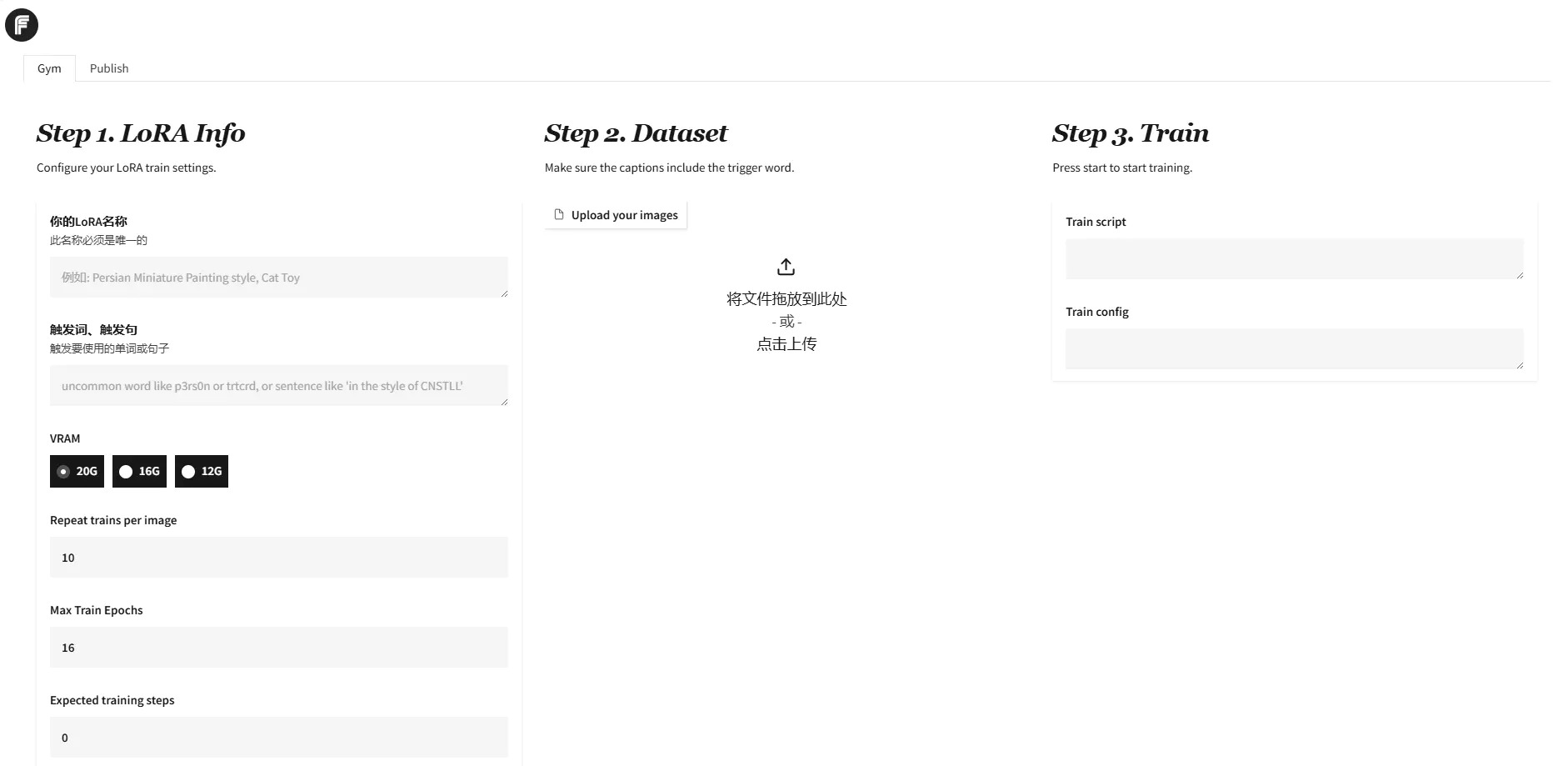
如果指定了端口,就访问自己指定的端口,否则默认的端口会是7860,你也可以直接复制控制台的地址进行访问。
最后是模型下载和修改模型models.yaml文件。
模型下载的代码如下:
import os
import requests
from concurrent.futures import ThreadPoolExecutor
from tqdm import tqdm
# 下载任务配置(FP8精度版本)
download_tasks = [
{
"url": "https://hf-mirror.com/comfyanonymous/flux_text_encoders/resolve/main/clip_l.safetensors?download=true",
"save_path": "models/clip/clip_l.safetensors"
},
{
"url": f"https://hf-mirror.com/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp16.safetensors?download=true",
"save_path": "models/clip/t5xxl_fp16.safetensors"
},
{
"url": "https://cnb.cool/itq5/comfyui_models/-/lfs/afc8e28272cd15db3919bacdb6918ce9c1ed22e96cb12c4d5ed0fba823529e38?name=ae.sft",
"save_path": "models/vae/ae.sft"
},
{
"url": "https://cnb.cool/itq5/comfyui_models/-/lfs/062dad72b2fee99af172463b3a2c84c1da793aaf80eaa0543138e05be55cdbbf?name=majicflus_v134.safetensors",
"save_path": "models/unet/majicflus_v134.safetensors"
}
]
def download_file(url, save_path):
"""下载单个文件并显示进度条"""
# 创建保存目录
os.makedirs(os.path.dirname(save_path), exist_ok=True)
# 设置请求头(部分镜像站需要)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
# 设置流式下载
try:
response = requests.get(url, headers=headers, stream=True, timeout=30)
response.raise_for_status()
# 获取文件总大小
total_size = int(response.headers.get('content-length', 0))
# 检查是否已部分下载
if os.path.exists(save_path):
existing_size = os.path.getsize(save_path)
if existing_size == total_size:
print(f"文件已存在且完整: {save_path}")
return
elif 0 < existing_size < total_size:
headers['Range'] = f'bytes={existing_size}-'
response = requests.get(url, headers=headers, stream=True, timeout=30)
# 使用tqdm显示进度条
progress_bar = tqdm(
desc=os.path.basename(save_path),
total=total_size,
unit='B',
unit_scale=True,
unit_divisor=1024,
initial=existing_size if 'Range' in headers else 0
)
# 写入文件(追加模式如果支持断点续传)
mode = 'ab' if 'Range' in headers else 'wb'
with open(save_path, mode) as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
progress_bar.update(len(chunk))
progress_bar.close()
# 验证文件完整性
if total_size != 0 and os.path.getsize(save_path) != total_size:
raise Exception(f"下载不完整: {save_path}")
except Exception as e:
# 清理不完整的文件
if os.path.exists(save_path):
os.remove(save_path)
raise Exception(f"下载失败: {url} -> {str(e)}")
def download_all():
"""多线程下载所有文件"""
print("开始从国内镜像站下载FP8精度模型...")
print("使用的镜像站: MIRROR_URL")
with ThreadPoolExecutor(max_workers=4) as executor:
futures = []
for task in download_tasks:
futures.append(
executor.submit(
download_file,
task["url"],
task["save_path"]
)
)
# 等待所有任务完成
for future in futures:
try:
future.result()
except Exception as e:
print(f"\n错误: {str(e)}")
print("\n所有下载任务完成!")
print("模型保存位置:")
for task in download_tasks:
print(f"- {task['save_path']}")
if __name__ == "__main__":
download_all()在虚拟环境中执行:
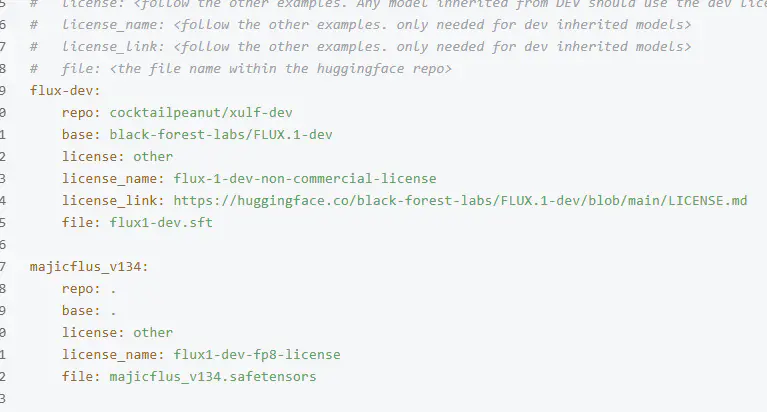
python down_models.py如果需要,可更改models.yaml的模型配置文件,自行选择需要的模型,以下是一个麦橘模型的案例,直接复制替换一组flux1-dev模型即可,如下:
majicflus_v134:
repo: .
base: .
license: other
license_name: flux1-dev-fp8-license
file: majicflus_v134.safetensors
失败,需检查是否在 fluxgym 目录下执行命令,确保路径正确;
依赖安装报错时,可尝试pip install –ignore-installed强制安装或手动补装缺失包(如gradio、torchvision)。
遇到端口被占用的情况,只需修改GRADIO_SERVER_PORT为其他未用端口(如 7860)并重启服务。
若模型下载缓慢,可手动从 Hugging Face 模型库下载文件并放入指定目录,避免程序自动下载的延迟。
国内用户可全程使用清华源、HF 镜像等加速渠道,同时提前从Nvidia 官网下载匹配的 CUDA 驱动,确保 PyTorch 运行顺畅。训练时建议关闭其他占用资源的程序,Windows 用户可通过任务管理器监控内存和显卡使用情况,Linux 用户可用nvidia-smi实时查看。此外,记录各组件版本(如 Git 提交哈希、Python 版本)至关重要,便于后续复现环境或回滚操作。
完成上述步骤后,你已成功搭建 Flux Lora 模型训练环境,接下来即可通过 Web 界面开启 AI 训练。期待你在留言区分享部署经验或遇到的问题,我将及时解答。